Sentiment Analysis - Improving Bayesian Methods
The code can all be found on GitHub: here
The point of this project is to explore practical and pragmatic means to improve results from Bayesian classifiers in the area of sentiment analysis.
This project explores a few optimizations to the typical Naive Bayesian methods for sentiment analysis along with a few notes.
Depending on your requirements you can achieve >90% accuracy with Bayesian techniques. Results of >99% accuracy are possible in aggregate.
The best results typically range from 89-94% accuracy while rating 50-70% of the data. As this is a stochastic method, results vary. All results are generated from a proprietary tokenizer, though I suspect the Lucene tokenizer will get close, or at least demonstrate the improvement over single Bayesian classifier.
-
Instead of using a single Bayesian classifier, we will train a small cluster of Bayesian classifiers on random samples of the training data (Bagging). (This offered the most immediate improvement)
- This is similar to the improvement
Random Forestprovides overDecision Treealgorithms. - The implementing class is called
Stochastic Bayesian Classifier - Choose your strategy for determining how the cluster of classifiers "vote" for the final sentiment. All-or-none, majority wins, average, etc.
- This is similar to the improvement
-
You don't have to rate 100% of the data.
- Depending on your business case, you may not have to rate 100% of your data. E.g. Rating 50% of the data is usually more than enough to get an idea of overall sentiment.
- The rated data just needs to be representative of the over all data.
- Adjust the confidence required for the classifier to apply a sentiment label.
-
N-Gram models can do pretty well.
- While skipgrams have potential to offer more language coverage with less data, they are also very expensive to compute.
- Bigrams seemed to hit the sweet spot for speed, accuracy, and memory.
-
Prune your trained model.
- Removing n-grams/features that occur "too rarely" can help prevent over-fitting, as well as decrease the model's memory footprint (~4x in these tests)
-
Tokenization of the text matters!
- This project contains two tokenizers, a naive white space tokenizer, and a more advanced Lucene standard analyzer. The Lucene standard analyzer does much better.
- At DataRank/Simply Measured, we use much more developed tokenizers that better handle language, emoji, urls, etc. This allows the model to have more structured information to learn from and offers significant improvement.
-
In practice, more important than individual text sentiment accuracy is the accuracy in aggregate.
- E.g. The algorithm achieves 90% accuracy for rating individual texts, however in aggregate it is 99.1% accurate.
- An example of an aggregate sentiment result is saying a set of text is 70% positive and 30% negative.
Why use Bayesian models?
There are plenty of alternative models to sentiment analysis, a few have been known to outperform Bayesian classifiers. Some of these include LTSM recurrent neural networks, SVM, Convolutional Neural Networks, etc.
I have implemented many different models, including some of the above mentioned models, and achieved success. So why use the simple-man's Bayesian classifier?
If you have ever had to debug why a classifier is wrong or right about it's results or had to retrain a large neural network or SVM, then you probably know the difficulty that comes with managing these technologies. They are also surprisingly difficult to explain to customers (this may or may not be relevant). Imagine explaining to your customer or boss how the neural network mis-learned certain word pairs due to how the word vectors were encoded. This can even be difficult for an engineer to debug. Retraining and testing large models can also be very time consuming considering some models may take hours retrain and verify.
Often times the gains of these algorithms (a few percents of accuracy), may not outweigh the aforementioned costs. Also A Bayesian classifier is incredibly easy to debug (just look at the word/n-gram probabilities). They also train about as fast as you can tokenize, compute n-grams and pump the data into the model.
Results
Imdb Movie Review Test
-
(Scroll to the bottom for instructions on downloading the IMDB movie review dataset.)
-
singlemodel = single Bayesian classifier.stochasticmodel = cluster of random sampling Bayesian classifiers. (bagging)
Results generated from BayesianClassifierImdbDemo.kt
Confidence Threshold: 0.25
| Model | Train+ | Train- | Test+ | Test- | Net Accuracy | % of data rated | Misc Parameters | |
|---|---|---|---|---|---|---|---|---|
| stochastic bigram | 98.7% | 97.1% | 94.8% | 92.8% | 93.8% | 61.0% | classifier count: 10, sampling rate: 0.2 |
Confidence Threshold: 0.2
| Model | Train+ | Train- | Test+ | Test- | Net Accuracy | % of data rated | Misc Parameters | |
|---|---|---|---|---|---|---|---|---|
| stochastic bigram | 99.5% | 97.7% | 94.8% | 89.1% | 91.95% | 54.4% | classifier count: 10, sampling rate: 0.2 | |
| stochastic skipgram(2,2) | 98.5% | 97.3% | 89.1% | 87.4% | 88.3% | 37% | default | |
| single bigram | 99.98% | 100.0% | 70.9% | 77.2% | 74.0% | 73% | default | |
| single skipgram(2,2) | 100.0% | 100.0% | 69.3% | 72.0% | 70.7% | 70.5% | default |
Confidence Threshold: 0.05
| Model | Train+ | Train- | Test+ | Test- | Net Accuracy | % of data rated | Misc Parameters | |
|---|---|---|---|---|---|---|---|---|
| stochastic bigram | 99.6% | 99.5% | 92.8% | 96.5% | 94.6% | 16% | classifier count: 10, sampling rate: 0.2 | |
| stochastic skipgram(2,2) | 99.8% | 98.9% | 93.8% | 92.05992% | 92.8% | 15% | default | |
| single bigram | 100.0% | 100.0% | 77.3% | 77.3% | 77% | 72% | default | |
| single skipgram(2,2) | 99.7% | 99.4% | 94.1% | 94.7% | 94.2% | 10% | default |
Tweet Test
Results Generated from StochasticBayesianClassifierTwitterSampleDemo
| Model | Train+ | Train- | Test+ | Test- | Net Accuracy | % of data rated | Misc Parameters | |
|---|---|---|---|---|---|---|---|---|
| stochastic bigram (kaggle data) | 100.0% | 99.9% | N/A | N/A | 99.95% | 95.7% | classifier count: 15, sampling rate: 0.5 | |
| stochastic bigram (hand rated) | 99.8% | 99.9% | N/A | N/A | 99.85% | 80.5% | classifier count: 15, sampling rate: 0.5 | |
| stochastic bigram (hand rated, 50% train, 50% test) | 99.8% | 99.9% | 86.3 | 95.9 | 91.1% | 64.2%% | classifier count: 15, sampling rate: 0.5 |
Aggregation Testing
Refer to sentiment_analysis.xlsx file for more details.
| Simulations | Sample Size | Percent Positive | Average Error | Standard Deviation | Data Set |
|---|---|---|---|---|---|
| 100 | 1000 | 50% | 0.031 | 0.019 | Imdb |
| 100 | 2000 | 50% | 0.010 | 0.013 | Imdb |
| 100 | 2000 | 50% | 0.009 | 0.010 |
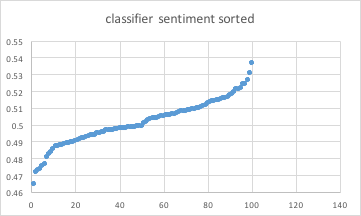
This below graph shows hows how the classifier skews against data that is known to be 50% positive/negative. This skew is a plot of 100 simulations.

The below graph shows each of the classifier sentiment aggregations for each simulation, sorted, and then plotted.
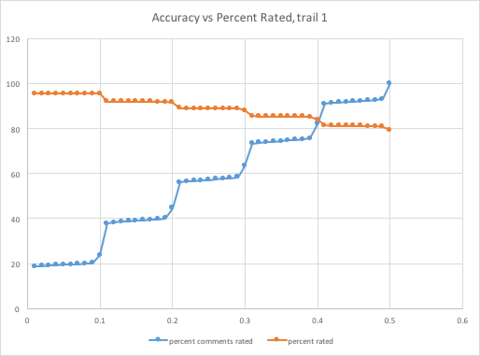
The below graph shows given a variable confidence threshold, [0.01, 0.50], the relationship between accuracy and percentage of data rated.
Performance
Model Pruning
| Min Frequency | Prune Threshold: abs(0.5 - p(pos)) < threshold | Avg size Before | Avg size Before | Accuracy Before | Rated Before | Accuracy After | Rated After | |
|---|---|---|---|---|---|---|---|---|
| 2 | 0.05 | 409534 | 130448 | 91.3% | 40% | 94.7% | 40% | |
| 2 | 0.05 | 413216 | 112896 | 91.9% | 40% | 95.2% | 43% |
Heap size Before and After Pruning of same model used in above tests: 888mb -> 335mb
Processing Speed
Pruned model:
- 37,153 reviews/min, 18 days to process 1 billion reviews
- 571,724 tweets/min, 29 hours to process 1 billion tweets
Data
Many thanks to the Stanford team to putting together the IMDB movie review dataset. There is a small sample of the IMDB movie review set included in the test resources for quick testing/experimenting. However, the full dataset can be found here
To download the IMDB movie review dataset and extract it, run:
wget http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
tar xvf aclImdb_v1.tar.gz
Make note of the output directory as the full path to the output will be passed into many of the IMDB "demo" programs.
Kotlin
This program is written in Kotlin, https://kotlinlang.org/, a JVM language that finds the sweet spot between Java and Scala to make an almost perfect language. I hope you enjoy it as much as I do. :)
 Arrived
Arrived
 Ninja Turdle
Ninja Turdle
 Twitch
Twitch